
이젠 약간의 쉬어가는 쉬는시간이자, 데이터베이스에 대해 좀 더 깊게 이해할 수 있는 지식을 배워볼 시간이다.
우린 데이터베이스를 사용해서
일상의 문제들을 손쉽고 간편하게 해결해주는 세상 속에서 살아가고 있다.
휴대폰으로 간편하게 어플의 서비스들을 이용해
이동할 지역까지의 최적경로를 찾을 수 있다.
친구들이나 비즈니스 관계에 있는 사람들과 커뮤니티 어플로 우린 직접 만나지 않아도,
전화 통화하지 않아도, 간편하게 연락할 수 있다.
정말 세상은 변화했고,
앞으로도 꾸준히 더 나은 세상이 되길 변화하는 중이다.
그런 삶의 변화를 가능케한 역할이
데이터베이스도 한 몫을 했다.
수많은 사람들의 데이터들을 저장하고,
서비스를 기능케한 저장 공간이 데이터베이스이다.
그렇다. 우린, 데이터베이스 라는 도구로
삶에서 수많은 가치를 얻어낸다.
그런 관점으로,
우린 데이터베이스 세상에 대해서 이해하고,
그에 맞춰 다가간다면, 우린 좀 더 변화하는 삶을 만들어내는 창조자로써
삶을 능동적으로 변화시킬 수 있지 않을까?
이러한 데이터베이스 세상에 대한 규칙을
"정규화"라고 한다.
어떤가, 정규화에 대해서 한번 같이 공부해볼까?
정규화
데이터베이스 세상의 규칙서, 가이드라인, 가이드북이다.
우린 데이터베이스를 사용해서 수많은 가치를 만들어내고 있다.
정말 한없이 많은 가치를 만들어왔고, 지금도
더 나은 사람들의 삶을 위해 새로운 가치를 만들어내고 있다.
이러한 무한한 가치를 만드는 데이터베이스에 대한
규칙과 방향성을 정립해둔 개념을
정규화다.

정규화 종류는
제 1 정규화부터 시작해 정말 많이 있다.
많이 알수록 좋긴하지만,
사실 상 데이터베이스를 활용하는 입장에선,
제 1 정규화부터 제 3 정규화만을 주로 다룬다.
이번 포스팅에선,
제 1 정규화, 제 2 정규화, 제 3 정규화를 하나씩 다룬다.
제 1 정규화
테이블 칼럼의 속성은 하나의 값만을 지녀야한다.
즉, 다음과 같이 표현된 테이블은
제 1 정규화를 위반한 테이블이다.
즉, 제 1 정규화에 따라
테이블의 모든 칼럼 속성들은 오직 하나의 값만을 지닐 수 있다.
제 1 정규화에 따라 테이블을 관리하면
다음과 같이 관리된다.
정리해서, 제 1 정규화는
"데이터베이스의 테이블 칼럼 속성은 오직 하나의 값만을 저장한다." 라는
규칙이다.
제 2 정규화
테이블의 칼럼들은 부분 종속성이 없어야 된다.
다시말해, 특정 칼럼들이 중복해서 테이블에 저장되는 경우를
부분 종속성을 가지고 있다고 한다.
다음과 같이 des, created, author_id, author_name, author_profile 칼럼들이
중복해서 데이터가 저장되는 경우를
제 2 정규화를 위반한 테이블이다.
이렇듯, 데이터가 중복해서 테이블에 저장되는 원인은
서로 다른 칼럼 그룹들이 하나의 테이블로 생성되어 발생한다.
다시 살펴보자.
제 2 정규화를 고려한 테이블은 어떻게 만들어질까?
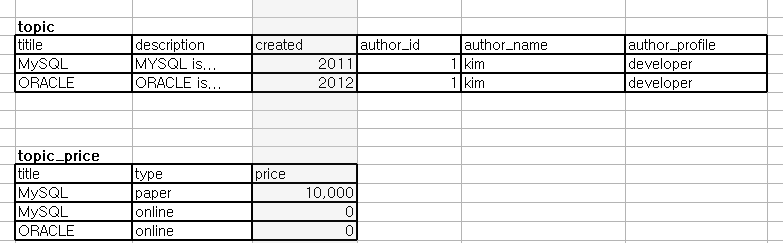
기존 테이블은
게시글과 게시글 가격에 대한 부분을 하나의 테이블로 생성했다.
게시글의 요소인 "내용, 저자 정보, 작성시간" 게시글 내용그룹과
"게시글 타입, 게시글 가격" 게시글 가격 그룹이 하나의 테이블에 존재했다.
즉, 게시글 제목에 대해
두가지 종속관계인
게시글 내용,
게시글 가격
이 존재하고 있어
데이터를 저장할 때 중복 데이터가 저장되고 있었던 것이다.
따라서,
제 2 정규화에 따라
부분 종속관계에 속한
게시글 내용, 게시글 가격을 서로 다른 테이블로 생성해
topic 테이블, topic_price 테이블로 분리해 부분종속 관계를 제거할 수 있었다.
정리해서,
제 2 정규화가 추구하는 목적은
"데이터베이스의 테이블의 모든 칼럼들은 공통의 하나의 동일한 목적 (기본키)을 지니고 있어야 된다."
라는 규칙이다.
제 3 정규화
테이블에서 이행적 종속관계가 없어야 된다는 규칙이다.
다시말해,
하나의 테이블에서, 서로 다른 기본키 역할을 수행하는 부분을 제거해야 된다는 뜻이다.
예시로 살펴보자.
아래는 제 3 정규화를 위반한 테이블이다.
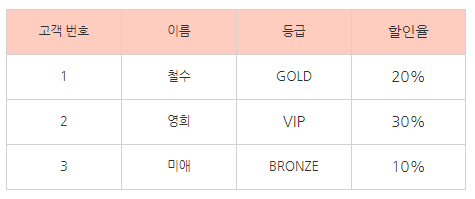
예시 상황은
백화점에서 고객의 등급 별로 할인율 정보를 제공하는
조회 서비스를 제공한다고 가정하자.
이에 따라,
고객은 고유한 고객 번호에 따라
고객 이름, 등급 정보를 알 수 있다.
그리고,
고객은 자신의 등급을 알면, 할인율을 알 수 있다.
그렇다.
고객 이름, 등급은
고객 번호에 종속하며,
고객의 할인율은
고객 등급에 종속한다.
즉, 서로 다른 종속관계의 연속인
고객 번호 <- 고객이름, 등급
등급 <- 할인율
이행적 종속관계라는 사실을 알 수 있다.
그러고, 위의 예시 테이블은 이러한 관계를
하나의 테이블에 생성해둬, 이행적 종속관계를 나타내었다는 사실을 알 수 있다.
그럼, 이제 다시 살펴보자.
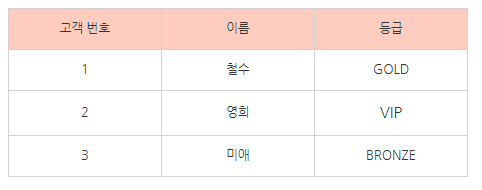
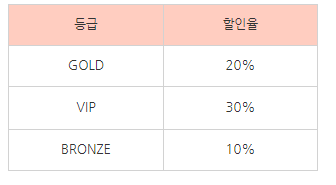
서로 다른 목적을 지닌 데이터들인
고객번호 <- 고객이름, 등급
등급 <- 할인율을
각각 고객 정보 테이블, 등급 별 할인율 테이블로
두 테이블로 분리시켜 생성했다.
이로써, 얻어지는 이점은
목적이 서로 다른 데이터들의 집합으로
중복 데이터가 저장되는 것을 방지한다.
정리해서,
제 3 정규화는
"데이터베이스에서 테이블은 서로 다른 의미로 인해 데이터가 중복되는 걸 막아야한다."
라는 규칙이다.
정규화를 마치며
정규화는 데이터 베이스 구조로 테이블을 설계할 수 있도록 도와주는 방법론이다.
제 1 ~ 3까지 순서대로 진행되는 방식이 아닌, 일종의 가이드라인으로 참고해서 ERD 설계를 돕는 안내서 역할이다.
결국 정규화를 필요로하는 이유는 데이터 베이스에 불필요한 중복, 이로인한 공간낭비, 데이터 처리 반복유발 등등 각 종의 문제상황들을 DB를 토대로 해결할 때 발생하는 불편을 해소시켜주자 정규화를 필요로 한다.
유저 이름 업데이트
유저 전번 업데이트
게시글 삭제 등등
우리가 살아가고 있는 상황들은 다양하고 복잡하게 엃혀있다.
"그러한 상황들을 간편하게 대처할 수 있는 데이터 베이스를 만들고자 정규화가 고로 존재한다."
라는 사실만을 이해하면
이번 포스팅을 충분히 잘 학습했다고 감히 말할 수 있다.
다음 포스팅은
데이터 모델링의 마지막 챕터인
역정규화에 대해서 알아보도록 한다.
역 정규화는 정말 시니어 DB 설계자가 되려는 사람들을 위한 포스팅이니,
이 점을 참고해서 봐주길 바란다.
끝까지 읽어주신 독자여러분께 감사인사를 드리며,이번 포스팅도 마무리하려 한다.
'📚 스터디 > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] 최적화 DB, 역정규화 [5] (0) | 2023.10.09 |
|---|---|
| [데이터베이스] 데이베이스 설계도, ERD 설계 [3] (3) | 2023.09.30 |
| [데이터베이스] ERD 그게 뭔데? [2] (0) | 2023.09.24 |
| [데이터베이스] 데이터 모델링의 시작, 개념적 데이터모델링 [1] (0) | 2023.09.17 |
| [데이터베이스] 데이터 모델링을 시작하며 (0) | 2023.09.16 |