
[데이터베이스] ERD 그게 뭔데?
ERD Entitity Relationship Diagram [ERD] 는 시스템의 엔티티들이 무엇이 있는지 어떤 관계를 가지고 있는지를 구조적으로 나타낸 다이어그램이다. 앞서, 개념적 데이터 모델링으로 기획 상황을 속성, 그
ceo-uk22.tistory.com
앞선, 포스팅으로 이론적인 개념으로 ERD에 대해서 알아보았다.
ERD 는 데이터베이스 표현으로 속성, 그룹, 관계를
칼럼, 테이블, PK,FK 로 바꾼 다이어그램이다.
이젠, 직접 ERD 설계를 해볼차례이다.
왜 ERD 설계를 해야될까?
ERD 에 대해 처음 접하는 사람이라면
이에 대해 의심의 여지가 충분히 있다.
데이터베이스 구성하는데,
왜 ERD 설계를 강조하는지 처음엔 이해가 되지 않는다.
"그냥, 바로 데이터베이스 테이블 구성하면 되지 않나..?"
"빨리 DB 구축하고 작업들어가지.. 뭐하는거지?"

그러나, 우리는 기억할 필요가 있다.
데이터베이스라는 도구를 사용하기 위해
그에 맞춰 개념들을 재정의하고 있다는 걸
그렇다. 우린
데이터베이스를 사용하고자
속성, 그룹, 관계 3가지 카테고리로 쪼갰다.
이젠, 쪼갠 것을 다시 합칠 시간이다.
Table, Column, PK,FK 로 바꿔
데이터베이스 표현으로
일상에서 정의했던 문제들이 표현될 수 있도록 ERD 설계를 진행한다.
이는 쉽게 설명하면,
유럽으로 10박 11일 해외여행을 간다고 하자.

우린 유럽 국가를 여행하기란, 정말 소중하다.
멀기도 멀고, 여행 비용도 엄청 비싸기 때문이다.
유럽여행은, 하루하루가 정말 소중하다.
그런 여행에서
계획없이 유럽여행을 간다고 생각해보자.
공항에 내렸는데, 어디로 나가야되고
어디로 가야되고, 어디서 숙박해야되는지..
혼란스럽지 않은가?
ERD 설계 행위는
유럽 여행을 가기 전 세우는 계획과 같다.
데이터베이스를 사용해 문제를 해결하기 전에
데이터베이스 표현으로 쪼개고
다시 합쳐 ERD를 완성한다.
그렇게 완성된 ERD 기반으로
앞으로 사용할 데이터베이스를 구축한다.
유럽여행하며 혼란스럽지 않게,
여행계획을 세운다.
우리도 문제를 해결하며 혼란스럽지 않게
ERD 설계를 진행한다.
ERD 설계
앞선, 포스팅에서
ERD 구성요소들을 하나씩 살펴보며,
나아가 개념적데이터 모델을
ERD 구성요소로 어떻게 정의해야되는지까지 배웠다.
이젠, 직접 ERD 설계를 시작할 시간이다.

ERD 설계 툴
AQueryTool
AQueryTool은 웹 기반 ERD 툴 + SQL 자동 생성 프로그램입니다.
aquerytool.com
다양한 ERD 설계 툴이 존재한다.
나는 AQuery Tool을 사용해 ERD 설계를 진행한다.
Table 생성
AQuery Tool을 토대로
ERD를 쉽게 구성할 수 있다.
테이블 추가 옵션을 클릭해
테이블을 생성한다.

테이블 이름을 설정하고,
각 속성들을 추가해준다.
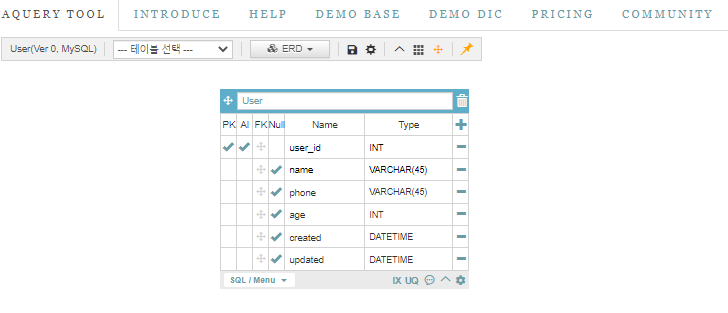
그렇게, 개념적 데이터모델에 따른 모든 테이블들을 생성해주고,
각 테이블 별 PK 설정을 지정해준다.
(PK란, 테이블을 대변하는 대표 키이자, 기본키이다.)
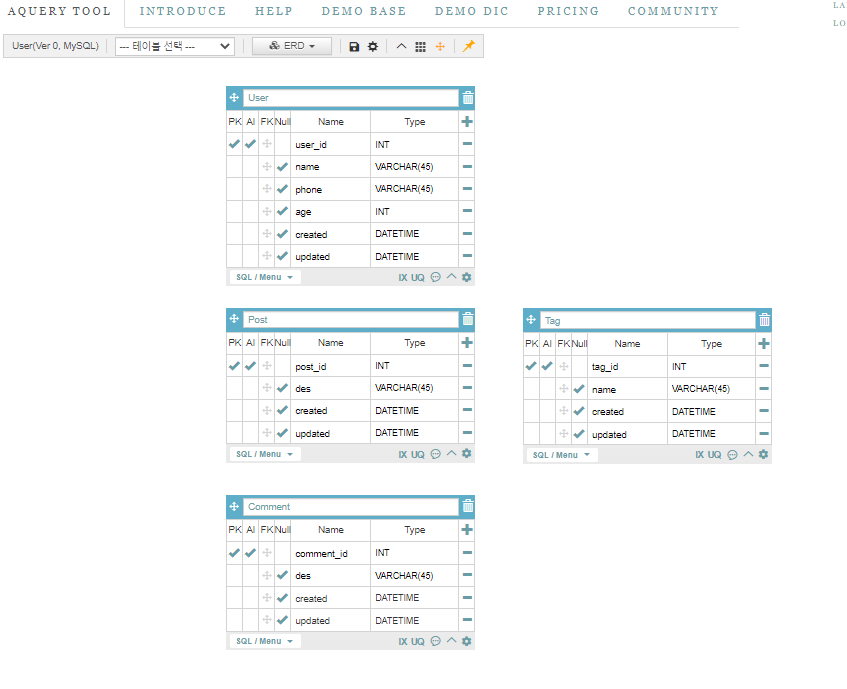
이젠, 쪼개놓은 테이블들이
기획했던 기능들을 동작할 수 있게
관계 생성으로 합체시키면 ERD 설계는 끝난다.
다시한번 말하지만, 우린 데이터베이스라는 도구를 사용하기 위해
여러 Table로 쪼갰다.
이젠, 관계를 연결함으로써 합쳐주는 과정을 진행하는 중이다.
관계 생성
관계는 테이블에 외래키 속성을 추가해줌으로써 관계가 설정된다.
외래키는 두 테이블을 서로 연결하는 데 사용되는 키
로써, 기본키로 이뤄진다.
우린 고유한 이름과 주민번호를 가지고 있다.
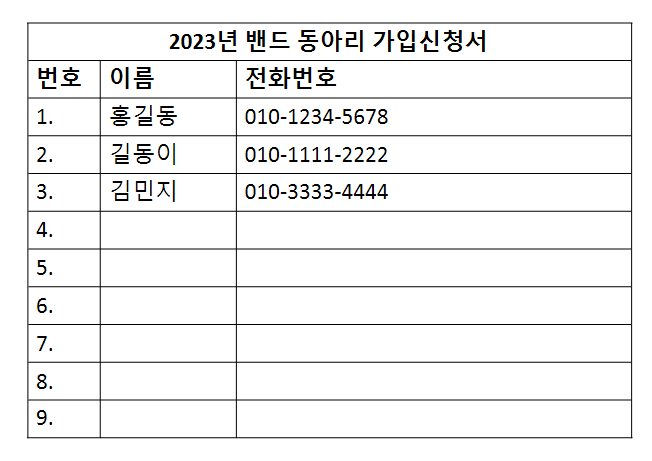
밴드 동아리에 가입한다고 생각해보자.
밴드 동아리는 여러 회원들을 모집하기위해, 동아리 가입신청서가 있다.
가입 회원들을 모집하고 연락하기 위해
신청서에는 전화번호를 작성하는 칸이 있다.
그렇다.
밴드 동아리 가입신청서의 전화번호가
외래키와 비슷한 역할을 수행한다.
따라서, 밴드 동아리에서 전화번호 정보를 추가함으로써,
회원과 연락할 수 있듯이
테이블에 외래키를 추가함으로써,
다른 테이블과 연결된다.
그럼, 이제 외래키를 사용해
모든 관계들을 연결시키는 방법들을 알아보자.
1 : 1 관계 생성
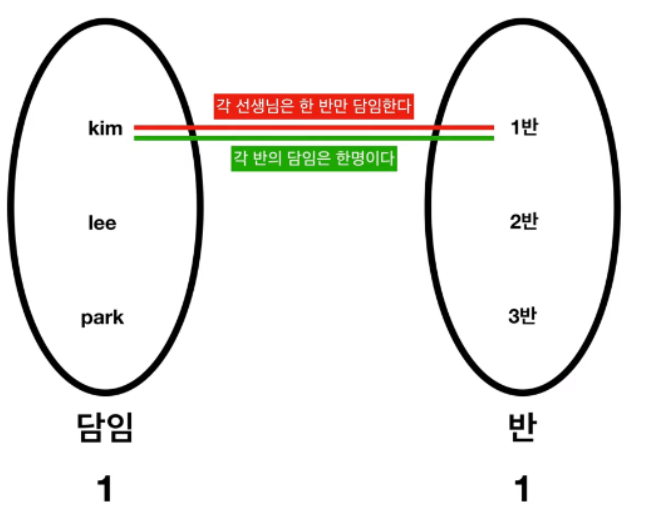
가장 단순한 관계인 1 : 1 관계는 다음과 같다.
1 : 1 관계는 외래키를 어떻게 생성할까?
1 : 1 관계에선
외래키를 가지고 있는 테이블에선,
기본키이자 외래키 역할을 수행한다.
다시말해, 기본키가 외래키 역할을 맡는다.
왜냐, 1 : 1 관계는
데이터가 있다면,
다른 데이터가 무조건 하나 혹은 존재하지 않기 때문이다.
예로들면,
반이 존재하면, 무조건 담임이 한명이고,
반이 존재하지 않으면, 담임은 없다.
따라서, 1 : 1 관계에선
두 테이블의 의존성을 토대로 테이블에 외래키를 부여한다.
반이 존재하면, 담임은 한명이다.
반이 존재하고, 담임이 없을 수도 있다. (반은 편성되었으나, 담임은 아직 없다.)
반대로, 담임이 있고, 반이 존재할 수 있다?
라는 말은 불가능하다. (담임이라는 직책은 반이 편성되고 부여된다.)
이에 따라,
반 과 담임의 관계는
담임은 반에 의존하는 관계로,
반이 부모 테이블,
담임이 자식 테이블이다.
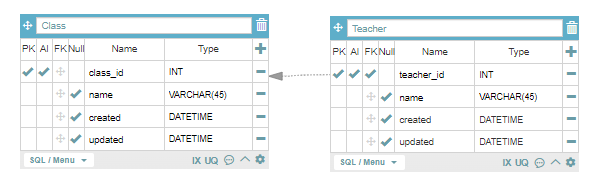
정리해서, 1 : 1 관계에선
의존성에 따라 자식 테이블에 외래키를 생성해
1 : 1 관계를 생성한다.
1 : N 관계 설계
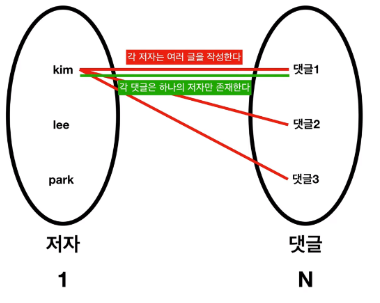
서비스를 개발하는 과정에서 가장 많이 접하는 관계, 1 : N 관계는 다음과 같다.
1 : N 관계는 외래키를 어떻게 생성할까?
간단하다.
N의 위치에 있는 테이블에 외래키를 생성해준다.
여러 데이터들에 대해선 주인이 있다.
(홀로 존재하는 데이터란 없다.
모든 지식, 생명들이 연결되어있듯 데이터또한 똑같다.)
유저는 블로그 게시글에 댓글을 남기면,
어떤 댓글이 내가 작성한 지를 구분되야 한다.
어떤 한 유저는 여러 댓글을 작성하거나, 댓글을 하나만 작성하거나, 댓글을 작성하지 않을 수 있다.
우린, 이와 같이 유저들이 작성하는 여러 댓글들을
구분해줘야한다.
따라서, 댓글에 누가 작성했는지에 대한 유저 기본키를 넣어
댓글을 조회했을 때 누가 작성했는지 보여줄 수 있다.
즉, 댓글 테이블에 유저 테이블의 기본키인 "유저 Id"를
외래키로 생성한다.
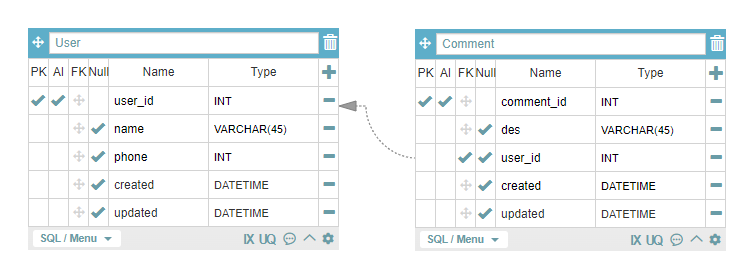
정리해서,
데이터는 홀로 존재하지 않는다.
여러 데이터가 있다면, 무엇과 연결되어 있는지를 분명하게 정의해야된다.
1 : N 관계에선
N의 위치에 있는 테이블에 외래키를 해줌으로써
완전하게 관계를 연결한다.
N : M 관계 설계
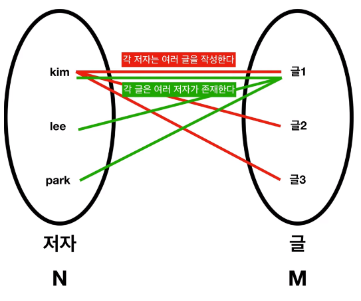
다대다 관계라고 불리는 N : M 관계는 다음과 같다.
N : M 관계는 외래키를 어떻게 생성할까?
해당 관계에선, 구분이 필요한 기본키가 두개이다.
즉, 연결되지 않은 기본키가 하나가 아닌 두개로 존재한다.
N : M 관계를 데이터베이스 상에서 2개의 테이블로 표현하기란 어렵다.
그래서, 별도의 추가 테이블인 "매핑 테이블"을 추가해서
N : M 관계를 1 : N 관계로 표현할 수 있도록 돕는
추가적인 테이블 "매핑 테이블"을 생성해
N : M 관계를 표현한다.
예를 들어보자,
놀이동산은 여러 명의 손님을 받고,
손님은 여러 개의 놀이기구를 이용할 수 있다.
이때, 놀이동산 관리자가 되었다고 생각해보자.
Q1. 오늘 어떤 특정 손님이 이용한 놀이기구는 뭘까?
Q2. 롤코 놀이기구를 탑승한 모든 손님들은 누가 있을까?
우린 "놀이기구 이용일지" 를 토대로
쉽게 찾을 수 있다.
”놀이기구 이용일지”
손님 1 - 롤코 탑승
손님 1 - 회전목마 탑승
손님 2 - 롤코 탑승
손님 2 - 범퍼카 탑승
손님 3 - 롤코 탑승
손님 4 - 롤코 탑승
…
A1. 손님 1이 탑승한 놀이기구들은
-> 롤코, 회전목마
A2. 롤코 놀이기구를 탑승한 모든 손님들
-> 손님 1, 2, 3, 4
그렇다.
손님은 여러 놀이기구를 탑승할 수 있고,
놀이기구는 여러 손님들을 탑승시킬 수 있다.
즉, 다대다 관계이다.
만약, "놀이기구 이용일지" 없었다면, 해당 이해관계를 어떻게 풀어내야했을까?
손님, 놀이기구 탑승 내역들을 복잡하게 엃혀가며 이해관계를 해결했을 것이다.
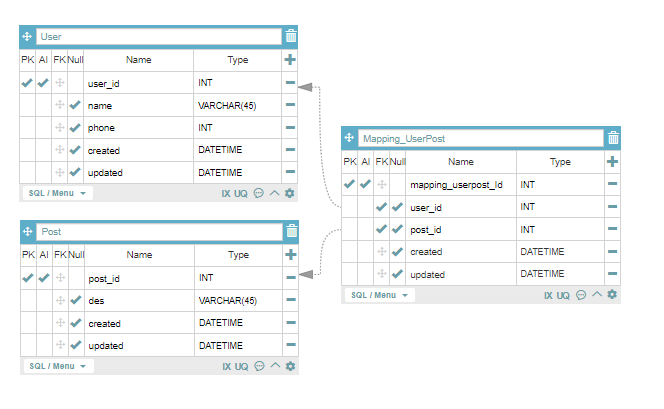
정리해서,
다대다 관계의 이해관계는
"놀이기구 이용일지"와 같은 두 관계를 연결시켜주는 매핑 테이블을 생성해 쉽고 간단하게 접근한다.
ERD 설계를 마치며
이제 ERD 설계까지 모두 완료했다.
여기까지 왔다면, 일상 기획상황을 데이터베이스로 풀어낼 수 있게
시스템화에 성공한 것이다.
정말 수고많았다.
서로 다른 영역을 연결하려는 작업은 참으로.. 추상적인 과정인 듯하다.
나 또한 이러한 이론적 지식들을 글로 정리하려 하니,
많이 힘들었다 ㅎㅎ..
우리 모두 잠시 밖에나가 환기를 시켜며
앞으로 목표를 잠시 다짐을 해보자.
이론적인 지식을 완벽하게 익히는 것은 좋다.
다만, 직접 삶에서 지식들을 사용하면서 경험을 쌓는 것이 더 없이 중요하다.
내 경험상, 이론적 지식을 습득만 하는 건
정말 지식일 뿐이다.
활용해서, 나만의 지식으로 연결시키는 것이 제대로된 학습이라는 사실을
이번 포스팅을 작성하면서 많이 깨달았다.
나는 백엔드 개발자로 활동을 하면서
데이터 모델링을 직접적인 경험을 통해 습득했다.
그리고, 군대에 온 지금은 이론적인 지식들을 구체적으로 정리하고자 강좌를 듣고
정리 포스팅을 작성했다.
확실히, 직접적인 경험이 베이스로 되어있으니,
지식들을 구조적으로 정리할 수 있었다.
그러니, 이 글을 읽고 있는 독자여러분들도
이론적인 지식들을 단순 지식저장으로만 남겨두기 말고,
활용해서, 자신만의 지식을 습득하길 바란다.
솔직히, 여기까지만해도, DB 활용한 백엔드 개발 프로젝트에 더할나위없이 참가할 수 있다고
난 생각한다.
그러니, 단순 지식 습득만을 고집하지 말고, 무언가를 해보자
내 경험상 이론적인 지식습득보다, 직접 경험해서 배우는 게 더 재미있고, 쉬웠다.
그러니, 너무 위축들지 말고 일단해봐라
그럼, 직접 경험을 하는 당신들을 위해 다음 포스팅을 준비해보겠다.
다음 포스팅은
안정적인 ERD 설계를 위한
가이드라인이자, 가이드북인 정규화에 대해서 포스팅해보려한다.
아마, 다음 부분부터는 시니어적인 스킬들을 습득하길 원하는 분들에게 읽기를 권장드린다.
'📚 스터디 > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] 최적화 DB, 역정규화 [5] (0) | 2023.10.09 |
|---|---|
| [데이터베이스] 데이터베이스 가이드북, 정규화 [4] (2) | 2023.09.30 |
| [데이터베이스] ERD 그게 뭔데? [2] (0) | 2023.09.24 |
| [데이터베이스] 데이터 모델링의 시작, 개념적 데이터모델링 [1] (0) | 2023.09.17 |
| [데이터베이스] 데이터 모델링을 시작하며 (0) | 2023.09.16 |