
AI 인공지능의 시대
2022년 말 Chat GPT가 세상에 공개되며, AI 붐이 시작되었다. 그리고, 비즈니스에서도 AI 기반 서비스들이 지금도 여럿 등장하고 있다. 필자도, Chat GPT를 여러번 이용한 적이 있으며, 현재 AI 수준은 과거보다 훨씬 많은 도메인 영역에서 응용되고 있음을 느꼈다. Saas 클라우드 컴퓨팅 시대 이후, AI 시대가 등장해 클라우드 서비스에서 AI 를 탑재하여 출시되기 까지 하고 있다.
"AI 모델을 개발하는 데에는 수많은 데이터와 복잡한 개발과정이 필요한데, 도대체, 세상에 많은 기업들은 비즈니스에서 AI를 어떻게 활용하는거지?"
필자는 위의 고민을 겪고, 10시간이상의 구글링과 여럿의 GPT 프롬프트 질문을 통해 해결할 수 있었다. 필자와 같은 고민을 지닌 사람을 위해 블로그 글로 작성했다.
사전학습된 인공지능 모델
인공지능의 능력을 보여주기 위해서는 복잡하게 얽힌 수많은 논리관계와 수식들이 내재되어 있다. 실제로 응용되는 인공지능은 수억개의 파라미터로 연산이 진행된다고 한다. 이처럼 복잡하게 설계된 인공지능을 실제 서비스에 어떻게 활용할까? 라는 의문점이 있다.
인공지능 모델을 활용하면 된다. 수 조개에 달하는 데이터들을 학습시켜 특정 Task에 있어서 인공지능으로 구현된 인공지능 모델들이 시중에 존재한다.
텍스트 생성 모델을 예시로, GPT-4, BERT, Gemini, Megatron-LM 등의 모델이 존재한다. 여러 인공지능 모델들은 특정 Task(작업)에 맞춤으로 사전학습이 이루어진다. 사전학습된 인공지능 모델이 처리가능한 Task를 업스트림 태스크라고 부른다.
upstream task (업스트림 태스크)
사전학습된 인공지능 모델이 적절하게 처리할 수 있는 Task를 업스트림 태스크라고 부른다. 예시로, LLM 모델은 다음 단어 맞히기, 빈칸 채우기 등 대규모 말뭉치의 문맥을 이해하고 가장 적절한 텍스트 문장을 생성하는 Task를 수행한다.
downstream task (다운스트림 태스크)
인공지능 모델이 업스트림 태스크를 이용해 적절하게 처리할 수 있는 새로운 Task를 다운스트림 태스크라고 부른다. 이는 LLM 모델의 텍스트 생성 Task를 통해 프로그래밍 코드 생성 Task 또는 다국어 텍스트 생성 Task 등등의 새로운 Task를 수행하는 GPT-4, BERT 등등 모델의 예시가 있다.

전이학습
LLM 모델이 GPT-4, BERT와 같이 여러 도메인의 텍스트 생성 모델로 개발되어질 수 있었던 건 "전이학습" 배경이 뒷받침이 있었다. 그렇다. 생성형 AI가 2023년도 붐을 일으킬 수 있었던 계기 중 일부, 전이학습이 관여가 있다.
전이학습은 특정 태스크를 학습한 모델을 다른 태스크 수행에 재사용하는 기법을 가리킨다. 위의 사진은 전이학습을 나타낸다. 태스크 2를 수행하는 모델을 가정해볼 때, 모델이 태스크 2를 학습할 때, 태스크 1을 수행했던 경험을 재활용한다.
이처럼 전이학습은 사전학습된 모델로 새로운 태스크를 수행할 수 있는 맞춤 데이터셋으로 학습이 진행된다.
다시말해 모델을 개발할 때, 처음부터 방대한 규모 데이터로 학습시킬 소요없이, 전이학습은 기존 사전학습 모델의 태스크와 맞춤 데이터셋으로 새로운 태스크를 처리하는 모델을 개발할 수 있다.
따라서, 전이학습으로 인공지능 모델 개발의 학습 비용과 속도를 줄일 수 있는 강력한 이점이 있기에 딥러닝 기반 인공지능 모델 개발에서 주로 활용되고 있다.
Fine-Tuning (파인 튜닝)
downstream task의 데이터 셋 전체를 사용하여, 다운스트림 데이터에 맞춘 모델 전체를 업데이트하는 학습
사전학습된 모델 전체의 파라미터를 미세조정하는 과정으로 다운스트림 태스크를 정확하게 해결하는 모델을 개발할 수 있다. 다만, 모델의 업스트림 태스크 수행능력이 감소될 수 있는 가능성이 존재하기에, 파인튜닝은 이러한 점을 고려해 학습 데이터 셋을 구성해야된다.
예시) Figma UI 추천 생성 AI, 고객 마케팅 챗봇 AI 등등
Prompt-Tuning(프롬프트 튜닝)
downstream task의 데이터 셋 전체를 사용하여, 다운스트림 데이터에 맞춘 모델 일부를 업데이트하는 학습
파인튜닝과 달리, 모델 일부 파라미터를 미세조정하는 과정으로 모델의 업스트림 태스크 수행능력 기반 다운스트림 태스크를 적절히 해결하는 모델을 개발할 수 있다. 업스트림 태스크 수행능력을 직접 연결하여 다운스트림 태스크를 수행하기에, 사전학습된 모델의 업스트림 태스크 수행능령을 철저히 이해하여, 가장 적절한 다운스트림 태스크를 수행할 수 있도록 학습 데이터 셋을 구성해야 한다.
예시) 페르소나 Chat AI, 스픽의 영어 Talk AI 등등
In-Context Learning
downstream task의 데이터 셋 일부만을 사용하고, 모델 업데이트는 수행되지 않는 학습
모델의 파라미터를 미세조정하지 않기에, 업스트림 태스크 수행능력과 모델 입력으로 제시되는 다운스트림 데이터 셋에만 의존하여 다운스트림 태스크를 수행한다. 업스트림 태스크 수행능력을 철저히 이용해, 다운스트림 태스크를 해결하는 과정을 뜻한다.
예시) ChatGPT로 동아리 모집공고글, 개인 영화 리뷰 블로그 작성 등등
<실습> LLM 모델의 프롬프트 튜닝
필자는 전이학습의 이해를 높히고자,
LLM 모델 기반 Bloom 텍스트 생성모델을 활용해 프롬프트 튜닝을 진행해보았다.
bigscience/bloom · Hugging Face
BigScience Large Open-science Open-access Multilingual Language Model Version 1.3 / 6 July 2022 Current Checkpoint: Training Iteration 95000 Link to paper: here Total seen tokens: 366B Model Details BLOOM is an autoregressive Large Language Model (LLM), tr
huggingface.co
Bloom 모델 개요
Transformer 기반 LLM 모델로, (BigScience)프랑스 정부에서 2022년 3월 ~ 2022년 7월 기간동안 산업규모의 계산리소스를 사용해 방대한 양의 텍스트 데이터에 대한 프롬프트에서 텍스트를 이어가도록 학습된 LLM 모델이다.
- 모델 아키텍처
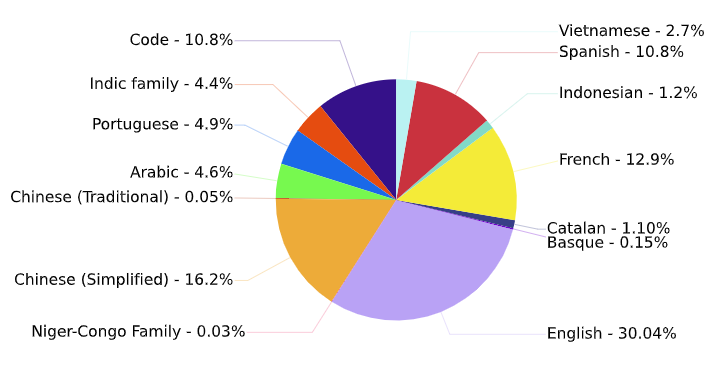
1,700억개 파라미터로 구성 - 훈련 데이터 셋 구성
개발환경
필자의 개발환경은 Google Colab에서 GPT T4 하드웨어 런타임을 사용했다.
필요한 패키지 설치
pip install -q peft==0.4.0
pip install -q transformers
pip install -q datasets프롬프트 튜닝 프레임워크인, peft 패키지를 사용했다. 학습 데이터 셋은 datasets 패키지 속 2,000여개의 학자의 명언 텍스로 사용했다.
필요한 라이브러리 불러오기
# 트랜스포머 라이브러리에서 사용할 클래스, 기능 가져오기
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer, DataCollatorForLanguageModeling
# 데이터셋 라이브러리
from datasets import load_dataset
# peft 라이브러리
from peft import get_peft_model, PromptTuningConfig, TaskType, PromptTuningInit, PeftModel, PeftConfig
# huggingface_hub 라이브러리
from huggingface_hub import notebook_login
import os
import time
사전학습된 모델 불러오기 <Bloomz-560m>
#사용할 사전 학습 모델 지정
model_name = "bigscience/bloomz-560m"
#사전 학습 모델에 사용할 tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
#지정한 모델 이름 사용해 사전 학습된 casual LM 로드
foundation_model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True)
사전학습 모델 텍스트 생성 (프롬프트 튜닝 전, 생성값 추론)
# 지정된 토크나이저 사용해 입력 텍스트 토큰화
input1 = tokenizer("Two things are infinite:", return_tensors = "pt", padding = True)
# input_ids와 attention_mask 기반해 사전 학습된 파운데이션 모델 사용해 텍스트 생성 요청
foundation_outputs = foundation_model.generate(
input_ids = input1["input_ids"],
attention_mask = input1["attention_mask"],
max_new_tokens = 7,
eos_token_id = tokenizer.eos_token_id
)
# 생성된 token id를 사람이 읽을 수 있는 텍스트로 디코딩
decoded_output = tokenizer.batch_decode(foundation_outputs, skip_special_tokens = True)
# 디코딩된 텍스트 출력(생성된 결과물 사람이 읽을 수 있는 형태로 출력)
print(decoded_output)출력결과 -> ['A love is a desire to be loved .']
학습 데이터셋 로드 및 토크나이징
# dataset 라이브러리 내 load_dataset 기능 활용해 "english_quotes" 데이터셋 가져오기
data = load_dataset("Abirate/english_quotes")
# 지정된 토크나이저 활용해 데이터셋 명언 토큰화
data = data.map(lambda samples:tokenizer(samples["quote"]), batched = True)
# 훈련 샘플 일부 선택(처음 50개)
train_sample = data["train"].select(range(50))
# train_sample 출력해보기
display(train_sample)tokenizer를 이용해, 텍스트 모델 입력이 이해할 수 있게 텍스트로 이뤄진 학습 데이터 셋을 토큰화시킨다.
프롬프트 튜닝모델 생성
# PromptTuningConfig 클래스 사용해 프롬프트 튜닝 Config 생성
peft_config = PromptTuningConfig(
task_type = TaskType.CAUSAL_LM,
prompt_tuning_init = PromptTuningInit.RANDOM,
num_virtual_tokens = 32, # 가상 토큰의 수 변경 (4 -> 8, 2배 증가)
tokenizer_name_or_path = model_name
)
# 지정한 파운데이션 모델과 프롬프트 튜닝 Config 사용해 PeftModel 가져오기
peft_model = get_peft_model(foundation_model, peft_config)
# 학습 가능한 PeftModel의 파라미터 출력
print(peft_model.print_trainable_parameters())사전학습 모델의 일부 파라미터 값을 커스텀으로 설정한다. 필자는 가상 토큰 수를 32로 설정하여, 32,728개 파라미터 값을 랜덤으로 초기화 시켰다.
이때, 초기화 방식은 랜덤 제외 다른 방법들이 존재한다. PEFT 명세서 참조
학습 요소 설정 및 학습시작
# Peft 모델에 대한 훈련 요소 정의
training_args = TrainingArguments(
output_dir = "./",
use_cpu = False, # GPU 사용
auto_find_batch_size = True, # 자동으로 메모리에 맞는 최적의 batch size 탐색
learning_rate = 3e-2, # 전체 파인튜닝할 때보다 학습률 높게 설정
num_train_epochs = 5 # 전체 파인 튜닝 데이터셋이 몇 번에 나눠서 통과하는 횟수
)학습 요소는 auto_find_batch_size 로 최적 batch size 탐색하고, 학습률, 에포크를 정의한다.
# Peft 모델 configuration에서 gradient checkpoint 활성화
peft_model.config.gradient_checkpointing = True
# Peft 모델 학습하기 위한 Trainer 인스턴스 생성
trainer = Trainer(
model = peft_model, # peft 버전 기본 모델인 bloomz-560M 전달
args = training_args, # 위에서 정의한 GPU 사용, 배치 크기 등 훈련요소에 따라 학습지침
train_dataset = train_sample, # 학습 데이터
data_collator = DataCollatorForLanguageModeling(tokenizer, mlm = False) #False: 마스크된 LM 사용하지 않음
)
# 학습 시작
trainer.train()Trainer 클래스를 이용해, 학습 요소와 데이터 셋 기반 학습을 진행한다.

프롬프트 튜닝된 모델 텍스트 생성
# 지정된 토크나이저 사용해 입력 텍스트 토큰화
input1 = tokenizer("What is the love ?", return_tensors = "pt", padding = True).to("cuda")
# input_ids와 attention_mask 기반해 사전 학습된 파운데이션 모델 사용해 텍스트 생성 요청
peft_model = trainer.model
peft_model_output = peft_model.generate(
input_ids = input1["input_ids"],
attention_mask = input1["attention_mask"],
max_new_tokens = 32,
eos_token_id = tokenizer.eos_token_id
)
# 생성된 token id를 사람이 읽을 수 있는 텍스트로 디코딩
decoded_output = tokenizer.batch_decode(peft_model_output, skip_special_tokens = True)
# 디코딩된 텍스트 출력(생성된 결과물 사람이 읽을 수 있는 형태로 출력)
print(decoded_output)출력 결과 -> ['The love is the only thing that can make you happy .']
<실습> LLM 모델의 프롬프트 튜닝 마치며
사전학습된 모델의 텍스트 생성결과
Q: What is the love ?
A: A love is a desire to be loved .
사랑은 사랑받고 싶은 욕망이다.
프롬프트 튜닝모델의 텍스트 생성결과
Q: What is the love ?
A: The love is the only thing that can make you happy .
사랑만이 당신을 행복하게 할 수 있는 유일한 것입니다.
사전학습된 Bloom 모델은 사전적인 표현으로, 텍스트 생성을 해낸 것에 반해,
프롬프트 튜닝된 모델은 학습 데이터셋 명언의 추상적인 표현으로 텍스트 생성을 해냈다. 이를 자세히 살펴보면, 사전학습된 모델(Bloom)의 텍스트 생성 태스크를 통해 유명학자의 명언 표현을 빌려 텍스트를 생성하는 새로운 태스크를 수행할 수 있는 모델이 만들어졌다. (이젠, Beautiful oom 모델이라고 부를 수 있지 않을까?ㅋㅋ 이름짓기 나름 ~)
비즈니스에서 인공지능 모델을 이처럼, 전이학습의 프롬프트 튜닝방식을 활용해 맞춤형 AI 모델로 개발한다면, 복잡하고 어려운 인공지능 개발에 걱정할 필요가 없다.
그러나, 변하지 않는 중요한 사실이 있다. 비즈니스에서 적절한 인공지능 모델을 택하고, 맞춤형 인공지능 모델을 개발하는 것이다. 지금도 인공지능 모델은 새롭게 다양한 방식으로 개발되어지고 있다. 아키텍처는 비슷할 지라도, 학습 시 사용되는 데이터 셋이 모두 다르며, 수행하는 태스크도 각자 다르다. 지금 AI 비즈니스가 가열되고 있는 시점에서 중요한 사실은 여러 모델들이 각자 어떤 태스크를 수행하는지를 이해하고, 맞춤형 AI 모델로 적용할 수 있는 것이다.
비즈니스에 더 효율적인 자원으로 맞춤형 AI 모델을 개발해내는 것이 앞으로 비즈니스에 있어서 중요한 Key Point가 될 것임이라고 생각한다.
다양한 AI 모델들을 학습하여, 효율적으로 맞춤형 AI 모델을 개발해내는 능력을 쌓아나가게 된다면,
앞으로 비즈니스 시장에서 굉장한 경쟁력을 지니지 않을까?